Capítulo 2 Formação da imagem
Existem diferentes tipos de fontes utilizadas para geração de imagens, sendo que a mais comum é o espectro eletromagnético na faixa de ondas visíveis. Outras fontes de energia também podem ser utilizadas como energia mecânica na forma de ultrassom, feixe de elétrons em microscópio eletrônicos, ondas de rádio no radar, etc. Cada fonte necessita de um método específico de captura. Para ondas eletromagnéticas pode ser usada uma câmera fotográfica equipada com sensores adequados ao comprimento de onda. Porém, para outras fontes, é necessário que o computador sintetize a imagem, como o microscópio eletrônico.
Como já mencionado no tópico de Introdução, o espectro eletromagnético contém diferentes frequências de energia, mas os humanos conseguem enxergar somente uma pequena parte desse espectro, conhecido como luz visível. Isso se deve ao fato de que nossos olhos evoluíram para serem sensíveis a essa faixa de luz, que vem da luz solar e nos ajuda a realizar nossas atividades cotidianas. Existem outros animais, como pássaros e insetos, que conseguem ver luz em outras faixas de onda, como a ultravioleta [8, p. 2]. Caso nossos olhos fossem também sensíveis a outras frequências, como por exemplo a de rádio, nossos celulares e torres telefônicas pareceriam lanternas [4, p. 8].
A luz sem cor, isto é, a luz com maior energia dentro do espectro visível humano, é chamada de luz monocromática (ou acromática). Pelo fato de a intensidade da luz monocromática ser percebida como variações de preto a tons de cinza até chegar ao branco, utiliza-se o termo nível de cinza ou escala de cinza. Já a luz cromática (colorida) cobre o espectro de energia eletromagnética na faixa de \(0.43\) a \(0.79 \mu m\). Além da frequência, três medidas básicas são utilizadas para descrever a qualidade de uma fonte de luz cromática: radiância, luminância e brilho. A radiância é a quantidade total de energia que é emitida pela fonte de luz e é normalmente medida em watts (W). A luminância, medida em lumens (lm), mede a quantidade de energia que um observador percebe de uma fonte de luz. O brilho, que incorpora a noção acromática de intensidade, é um descritor subjetivo da percepção da luz, então é praticamente impossível mensurar [2, p. 28].
Nos próximos tópicos iremos explorar alguns conceitos e o funcionamento da aquisição de imagem. Esse processo é um pouco complexo e envolve conceitos de ótica, que serão apresentados, de maneira introdutória, a seguir.
2.1 Câmera pinhole e geometria
Na Figura 2.1, temos um esquema básico de como geralmente ocorre a aquisição de imagens. Primeiramente, a energia em forma de luz, vinda de uma fonte, atinge um objeto e é refletida. A parte refletida é capturada por um dispositivo, como uma câmera fotográfica.
![Representação de uma típica captura de imagem [4, p. 8].](imagens/02-formacao/aquisicao_imagem.png)
Figura 2.1: Representação de uma típica captura de imagem [4, p. 8].
Baseado nesse princípio pode-se criar um dispositivo muito simples para captura de imagens, conhecido como câmera pinhole (do inglês buraco de alfinete) ou câmera escura. Este dispositivo consiste basicamente de uma caixa fechada com somente um pequeno orifício, tão pequeno quanto possível, por onde os raios de luz possam entrar. Mas por que utilizar somente uma pequena entrada? Como podemos ver na Figura 2.2, se tentarmos realizar a captura da imagem, usando filme fotográfico ou um sensor, sem essa limitação, a área sensível acaba recebendo raios de inúmeras direções, que acabam se misturando tendo como resultado uma imagem ruidosa. Com a barreira de entrada, limitamos a quantidade de luz e conseguimos resultados melhores.
![Introdução de barreira para captura de imagem [4, p. 11].](imagens/02-formacao/barreiraluz.png)
Figura 2.2: Introdução de barreira para captura de imagem [4, p. 11].
Na Figura 2.2 percebemos que a imagem resultante acaba invertida. Isso pode ser explicado através de algumas relações geométricas que serão apresentadas a seguir.
![Geometria de uma câmera pinhole [9, p. 5].](imagens/02-formacao/geometriapinhole.png)
Figura 2.3: Geometria de uma câmera pinhole [9, p. 5].
Na Figura 2.3, considerando que o eixo óptico corresponde a uma reta perpendicular ao orifício de entrada de luz, que o objeto está localizado a uma distância horizontal \(Z\) da abertura e a uma distância vertical \(Y\) do eixo óptico, podemos definir a altura \(y\) e a largura \(x\) da projeção do objeto utilizando a simetria de triângulos:
\[ -\frac{y}{f}=\frac{Y}{Z}\Leftrightarrow y=-f\frac{Y}{Z} \ \ \ \ \text{e}\ \ \ \ -\frac{x}{f}=\frac{X}{Z} \Leftrightarrow x=-f\frac{X}{Z} \tag{2.1} \]
A variável \(f\) nessa Equação (2.1) se refere a distância focal, que é, nesse caso, o tamanho da caixa da câmera, pois a imagem é formada em seu fundo [9, p. 4]. Os sinais negativos das equações significam que a imagem projetada está rotacionada a \(180^\circ\) verticalmente e horizontalmente devido a semelhança de triângulos [9, p. 5], como podemos confirmar na Figura 2.3. Câmeras que usavam esse princípio de funcionamento foram utilizadas a partir do século XIII mas hoje em dia não são utilizadas, somente por hobbistas ou curiosos, já que tem muitas desvantagens como precisar de um longo tempo de exposição para captura da imagem.
As câmeras mais modernas não possuem somente uma pequena entrada para luz, mas um sistema de lentes que focam a luz recebida no sensor. Discutiremos a seguir alguns dos conceitos por trás disso.
2.2 Lentes Finas
![Ação de uma lente sobre os raios de luz [4, p. 12].](imagens/02-formacao/lente.png)
Figura 2.4: Ação de uma lente sobre os raios de luz [4, p. 12].
Como podemos ver na Figura 2.4, em cada ponto de um objeto há inúmeros raios de luz refletidos - neste caso são ilustrados três - e os que chegam à lente são focalizados no seu lado direito. As imagens são capturadas colocando o sensor exatamente onde esses raios são focalizados, ou seja, onde a imagem é formada. O ponto \(F\) onde os raios paralelos se cruzam é conhecido como Ponto Focal. A distância \(f\), que vai do centro óptico \(O\) até \(F\) é conhecida como Distância Focal. Definindo a distância do objeto real até a lente como \(g\) e a distância até a formação da imagem, após passar pela lente, como \(b\) temos que:
\[ \frac{1}{g}+\frac{1}{b}=\frac{1}{f} \tag{2.2} \]
Como \(f\) e \(b\) estão normalmente entre 1mm e 100mm isso mostra que \(\frac{1}{g}\) não tem quase nenhum impacto na Equação (2.2) e significa que \(b = f\). Isso significa que a imagem dentro da câmera é formada muito próxima ao ponto focal. Outro ponto importante das lentes é conhecido como zoom óptico, ilustrado na Figura 2.5. Isto deriva de um aspecto das lentes de que o tamanho do objeto na imagem formada, \(B\), aumenta quando \(f\) aumenta. Podemos representar isso na seguinte Equação (2.3), onde \(g\) é o tamanho real do objeto:
\[ \frac{b}{B}=\frac{g}{G} \tag{2.3} \]
![Zoom óptico através de lentes com diferentes distâncias focais [4, p. 13].](imagens/02-formacao/proporcaoObjetoImagem.png)
Figura 2.5: Zoom óptico através de lentes com diferentes distâncias focais [4, p. 13].
Na prática \(f\) é alterado através de mudanças na distância entre diferentes lentes dentro do sistema óptico da câmera, aqui estamos usando somente uma lente para exemplificar de maneira fácil alguns de seus conceitos básicos. Se o \(f\) for constante, quando alteramos a distância do objeto, no caso \(g\), sabemos que \(b\) também aumenta, isso significa que o sensor tem que ser movido mais para trás, pois a imagem estará sendo formada mais longe da lente. Se não movermos \(b\) temos uma imagem fora de foco, como mostrado a seguir. Quando usamos uma câmera, o ato de colocar a imagem em foco significa que estamos alterando \(b\) para que a imagem seja formada onde o sensor está localizado, para que a imagem esteja em foco.
![Uma imagem focada em (a) e desfocada em (b) [4, p. 11].](imagens/02-formacao/foco.png)
Figura 2.6: Uma imagem focada em (a) e desfocada em (b) [4, p. 11].
A Figura 2.6 ilustra exatamente o que significa uma imagem estar fora de foco, no sensor cada pixel tem um tamanho específico, quando a imagem está em foco os raios de um ponto específico estão dentro da área do pixel. Uma imagem fica fora de foco quando os raios de outros pontos também interceptam o pixel, gerando uma mistura de diferentes pontos.
![Profundidade de campo [4, p. 13].](imagens/02-formacao/profundidade.png)
Figura 2.7: Profundidade de campo [4, p. 13].
A Figura 2.7 apresenta outro ponto muito importante, chamado Profundidade de Campo (Depth of field), que representa a soma das distâncias \(g_l\) e \(g_r\), que representam o quanto os objetos podem ser movidos e permanecerem em foco.
Um tópico que também tem muita importância na aquisição de imagens é o Campo de Visão (Field of View ou FOV) que representa a área observável de uma câmera. Na Figura 2.8, essa área observável é denotada pelo ângulo \(V\). O FOV de uma câmera depende de alguns aspectos, como sua distância focal e tamanho do sensor. Em muitos casos os sensores não são quadrados, mas retangulares, então para representarmos matematicamente o campo de visão, utilizamos as Equações (2.4) e (2.5), respectivamente, do campo de visão horizontal e vertical: \[ FOV_x = 2*\tan^{-1}\left(\frac{\frac{comprimento\ do\ sensor}{2}}{f}\right) \tag{2.4} \] \[ FOV_y = 2*\tan^{-1}\left(\frac{\frac{altura\ do\ sensor}{2}}{f}\right) \tag{2.5} \]
![Dois diferentes Campos de visão [4, p. 14].](imagens/02-formacao/campovisao.png)
Figura 2.8: Dois diferentes Campos de visão [4, p. 14].
Por exemplo, se tivermos uma câmera com um sensor que tenha o comprimento de \(14mm\), altura de \(10mm\) e uma distância focal de \(5mm\) temos: \[ FOV_x=2*tan^{-1}\left(\frac{7}{5}\right)=108.9^{\circ} \ \ \ \ \text{e}\ \ \ \ FOV_y=2*tan^{-1}(1)=90^{\circ} \tag{2.6} \]
Isso significa que essa câmera tem uma área observável de \(108.9^\circ\) horizontalmente e \(90^\circ\) verticalmente. Na Figura 2.9, temos o mesmo objeto fotografado com diferentes profundidades de campo:
![Objeto fotografado com diferentes profundidades de campo [4, p. 15].](imagens/02-formacao/diferentesprofundidades.png)
Figura 2.9: Objeto fotografado com diferentes profundidades de campo [4, p. 15].
Outros dois fatores importantes na aquisição de imagem são a abertura e o obturador. A abertura é, em uma câmera, o mesmo que a íris do olho humano. É ele que controla a quantidade de luz que chega ao sensor. E o obturador é um dispositivo que controla o tempo ao qual o sensor será exposto à luz para a captura da imagem.
2.3 Sensor
Existem dois tipos principais de sensores que são empregados em dispositivos fotográficos. Um deles é o CCD (Charge-coupled device), que é usado principalmente em aplicações mais específicas ou que precisam de uma qualidade muito alta, e o CMOS (Complementary metal–oxide semiconductor), usado em casos mais gerais, como câmeras de celulares. Após a luz passar por todo o sistema de lentes ela chega a esses sensores, que tem sua estrutura exemplificada na Figura 2.10, conhecido como PDA (Photodiode Array):
![Sensor (área matricial de células), Single Cell (uma única célula sensor) [4, p. 17].](imagens/02-formacao/sensor.png)
Figura 2.10: Sensor (área matricial de células), Single Cell (uma única célula sensor) [4, p. 17].
Como podemos ver, o sensor consiste em várias pequenas células, cada uma com um pixel, que recebe a energia luminosa e a converte para um número digital. Quanto maior a incidência de luz em um pixel, maior a quantidade de energia e por isso maior será o valor do número gerado. O trabalho de controlar esse tempo de exposição é do obturador da câmera, sendo que um tempo muito longo ou muito curto podem produzir efeitos indesejados nas imagens obtidas, por isso a maioria das câmeras contam com um sistema que controla automaticamente esse tempo para o melhor resultado. Na Figura 2.11, podemos ver isso em uma imagem real, na primeira temos uma imagem que foi capturada com a exposição correta (correctly exposed), logo em seguida temos uma que sofreu de superexposição (overexposed) e na terceira temos uma com subexposição (underexposed). Por último temos uma imagem que sofre com o movimento do objeto cuja imagem estava sendo capturada, o que ocasionou o borramento (motion blur).
![Diferentes níveis de exposição [4, p. 17].](imagens/02-formacao/exposicao.png)
Figura 2.11: Diferentes níveis de exposição [4, p. 17].
Vimos até agora, principalmente, como se capturam imagens em tons de cinza, mas como são capturadas imagens coloridas? Imagens coloridas utilizam, especialmente, o formato RGB, que significa Red-Green-Blue, ou seja, é formado pelas cores primárias vermelho, verde e azul. Podemos a partir disso gerar imagens coloridas tendo as informações sobre sua intensidade de cada uma dessas cores. Na Figura 2.12, podemos ver uma imagem com seus componentes separados:
![Imagem colorida separada em seus três componentes, em que Red é a vermelha, Green é a verde e Blue é a azul [4, p. 28].](imagens/02-formacao/componentes.png)
Figura 2.12: Imagem colorida separada em seus três componentes, em que Red é a vermelha, Green é a verde e Blue é a azul [4, p. 28].
Precisamos assim dessas três informações para formar uma imagem colorida, uma das implementações pensadas para resolver esse problema foi a de dividir a luz de entrada e enviar cada um dos raios filtrados para um sensor diferente, como representado na Figura 2.13. Apesar de essa implementação funcionar, ela não se tornou o padrão pelo fato de que utilizar três sensores faz com que seu preço de construção fique elevado e o projeto em si muito mais complexo.
![Captura de imagem com três sensores [10, p. 242].](imagens/02-formacao/tres_sensores.png)
Figura 2.13: Captura de imagem com três sensores [10, p. 242].
Ao invés disso, as câmeras modernas utilizam somente um sensor e fazem uso de um filtro que separa uma das três cores para cada pixel. Isso porque os fotodiodos não reconhecem por si só as cores, mas a intensidade, o que nos levaria a ter somente fotos com tons de cinza. Esse filtro pode conter diferentes configurações, sendo que uma das mais utilizadas é o filtro Bayer, que pode ser visto na Figura 2.14:
![Filtro Bayer [4, p. 29].](imagens/02-formacao/bayer.png)
Figura 2.14: Filtro Bayer [4, p. 29].
Podemos perceber que ocorre uma maior ocorrência das cores verdes. Isso se deve ao fato de que o olho humano é mais sensível a essa cor, logo se dá uma maior ênfase à sua captura. Na Figura 2.15, temos um esquema de como cada pixel recebe informação de somente uma cor, por meio da filtragem. Nesse esquema a luz que entra (Incoming light) é filtrada e somente a cor de interesse consegue passar. Após isso, ela chega a malha de sensores (sensor array):
![Sensores com padrão Bayer [11].](imagens/02-formacao/sensorarray.png)
Figura 2.15: Sensores com padrão Bayer [11].
Vemos na Figura 2.15 que temos ao final três grupos de informações diferentes mas que têm dados faltantes nos pixels referentes às outras cores. As informações desses pixels são preenchidas em um processo chamado interpolação que completa as informações baseada nos valores dos pixels vizinhos.
2.4 Amostragem e Quantização
Nas seções anteriores foram apresentados processos para a captura de imagens a partir de sensores (principalmente de câmeras comuns). Ainda como etapas da aquisição de imagens, serão abordados nesta seção a amostragem e a quantização, procedimentos em que os dados contínuos dos sensores são convertidos para o formato digital, que é discreto.
2.4.1 Amostragem
Na amostragem ocorre a discretização espacial, ou seja, a conversão de um espaço contínuo em um espaço discreto, que pode ser representado digitalmente. Este procedimento é exemplificado na Figura 2.16, na qual a Figura 2.16(a) representa um objeto de atributos contínuos, e a linha AB é um segmento horizontal do objeto.
A Figura 2.16(b) contém a representação da amplitude (nível de intensidade) da imagem contínua ao longo da linha \(\overline{AB}\). Nas extremidades do gráfico na Figura 2.16(b), a intensidade é mais alta devido a parte branca da imagem. Já os vales representam as partes com menos intensidade, ou seja, as partes mais escuras. Como o computador ainda não tem a capacidade de armazenar uma sequência infinita de números reais, então na quantização são selecionados pontos espaçados igualmente, como na Figura 2.16(c).
Na prática, esse procedimento de amostragem é realizado pelos sensores, nos casos mais comuns por um sensor de uma câmera, que geralmente é retangular. Desta forma, a quantidade de células sensíveis na matriz do sensor determina os limites da amostragem. Dito isso, percebe-se que para representar de maneira real o mundo, teríamos que ter um número infinito de pixels. Como isso não é possível, recorremos a opção de utilizar o maior número de pixels possíveis. Quanto mais pixels houver no sensor, maior será a quantidade de detalhes por ele capturado, melhorando a qualidade da imagem [2, p. 34].
![Produzindo uma imagem digital. (a) Imagem contínua. (b) Linha de varredura de \(A\) a \(B\) na imagem contínua utilizada para ilustrar os conceitos de amostragem e quantização. (c) Amostragem e quantização. (d) Linha de varredura digital. [2, p. 34]](imagens/02-formacao/amostragemquant.png)
Figura 2.16: Produzindo uma imagem digital. (a) Imagem contínua. (b) Linha de varredura de \(A\) a \(B\) na imagem contínua utilizada para ilustrar os conceitos de amostragem e quantização. (c) Amostragem e quantização. (d) Linha de varredura digital. [2, p. 34]
2.4.2 Quantização
Na Figura 2.16(c), os níveis de intensidade ainda variam dentro de uma faixa contínua. A função digital da intensidade é obtida pela quantização, em que as intensidades das amostras são mapeadas em um conjunto de quantidades discretas. Na Figura 2.16(d), os valores contínuos de intensidade são quantizados estabelecendo um dos oito valores para cada amostra de acordo com a escala de intensidade na Figura 2.16(c).
Na prática, geralmente a etapa de quantização é realizada diretamente no hardware utilizando um conversor analógico-digital [9, p. 8]. A conversão dos valores contínuos para valores discretos pode ser realizada por meio de arredondamento, truncamento ou algum outro processo [12, p. 9]. No processo de quantização, geralmente os níveis de intensidade são mapeados por uma transformação linear para um conjunto finitos de inteiros não negativos \(\{0,\dots, L-1\}\), onde \(L\) é uma potência de dois, ou seja, \(L = 2^k\) [12, p. 10]. Isso significa que \(L\) é o número de tons de cinza que podem ser representados com uma quantidade \(k\) de bits. Em muitas situações é utilizado \(k = 8\), ou seja, temos \(256\) níveis de cinza. Ao realizar a quantização e a amostragem linha por linha no objeto da Figura 2.17(a) é produzida uma imagem digital bidimensional como na Figura 2.17.
![(a) Imagem contínua projetada em uma matriz de sensores. (b) Resultado da amostragem e quantização da imagem. [2, p. 35]](imagens/02-formacao/quantizacao.png)
Figura 2.17: (a) Imagem contínua projetada em uma matriz de sensores. (b) Resultado da amostragem e quantização da imagem. [2, p. 35]
2.5 Definição de imagem digital
Uma imagem pode ser definida como uma função bidimensional, \(f(x, y)\), em que \(x\) e \(y\) são coordenadas espaciais (plano), e a amplitude de \(f\) em qualquer par de coordenadas \((x, y)\) é chamada de intensidade ou nível de cinza da imagem nesse ponto [2, p. 36]. Quando \(x\), \(y\) e os valores de intensidade de \(f\) são quantidades finitas e discretas, chamamos de imagem digital.
A função \(f(x, y)\) pode ser representada na forma de uma matriz MxN como na equação (2.7), em que as \(M\) linhas são identificadas pelas coordenadas em \(x\), e as \(N\) colunas em \(y\). Cada elemento dessa matriz é chamado de elemento de imagem, elemento pictórico, pixel ou pel. O formato numérico da matriz, imagem 2.18, é apropriado para o desenvolvimento de algoritmos, representado pela Equação (2.7).
\[f(x,y) = \begin{bmatrix} f(0,0) & f(0,1) & \cdots & f(0,N-1) \\ f(1,0) & f(1,1) & \cdots & f(1, N-1) \\ \vdots & \vdots & & \vdots \\ f(M-1,0) & f(M-1, 1) & \cdots & f(M-1, N-1) \end{bmatrix} \tag{2.7} \]
![Representações da imagem digital [2, p. 36].](imagens/02-formacao/imagemdigital.png)
Figura 2.18: Representações da imagem digital [2, p. 36].
Na Figura 2.18(a) temos a representação da imagem em 3-D, onde a intensidade de cada pixel é representada no eixo \(z\), ou seja, sua altura. Como a matriz numérica transmite pouca informação visual é comum uma representação como na Figura 2.18(b), formato que seria visualizado em um monitor ou uma fotografia [2, p. 36]. Em cada ponto da Figura 2.18(a), o nível de cinza é proporcional ao valor da intensidade \(f\), assumindo valores \(0\), \(0.5\) ou \(1\). Um monitor ou impressora simplesmente converte esses três valores em preto, cinza ou branco.
Note que na Figura 2.18, a origem de uma imagem digital se localiza na parte superior esquerda, com o eixo \(x\) positivo direcionado para baixo e o eixo \(y\) positivo para a direita. Esse padrão segue o comportamento de varredura de dispositivos de visualização de imagem, como os monitores de TV, que começam do canto superior esquerdo da imagem e se movem para a direita, fazendo uma linha por vez [2, p. 36]. De acordo com o tamanho da matriz (MxN) e dos níveis discretos de tons de cinza (\(L = 2^k\)) que os pixels podem assumir é possível determinar o número, \(b\), de bits necessários para armazenar uma imagem digitalizada:
\[ b = M × N × k \tag{2.8} \]
Quando uma imagem pode ter \(2^k\) níveis de intensidade, geralmente ela é denominada como uma “imagem de \(k\) bits”. Por exemplo, uma imagem com \(256\) níveis discretos de intensidade é chamada de uma imagem de \(8\) bits. A Figura 2.19 mostra o número de bits utilizados para armazenar imagens quadradas de dimensão (NxN) para diferentes valores de \(N\) e \(k\). O número de níveis de intensidade (\(L\)) correspondente a cada valor de \(k\) é mostrado entre parênteses. Observa-se na Figura 2.19 que uma imagem de \(8\) bits com dimensões 1024x1024 exigiria aproximadamente 1MB para armazenamento.
![Número de bits de armazenamento para vários valores de \(N\) e \(k\) [2, p. 38].](imagens/02-formacao/tabelabits.png)
Figura 2.19: Número de bits de armazenamento para vários valores de \(N\) e \(k\) [2, p. 38].
2.6 Resolução espacial e de intensidade
Sem as especificações espaciais da imagem, não se pode inferir sobre a qualidade apenas pelo tamanho (MxN) em quantidades de pixels. Outra medida para especificar a resolução espacial é a densidade de pixels, podendo ser expressa como pontos (pixels) por unidade de distância, comumente dots per inch (pontos por polegada ou dpi). Referências de qualidade em relação à resolução espacial são, por exemplo, jornais impressos com uma resolução de 75 dpi e páginas de livros geralmente impressas com 2400 dpi [2, p. 38].
A Figura 2.20 mostra os efeitos da redução da resolução espacial em uma imagem em seis resoluções diferentes. A Figura 2.20(a) tem resolução 512x512, e a resolução das demais 2.20(b-f) diminui pela metade de forma sequencial. Todas as imagens têm as mesmas dimensões, ampliando-se o tamanho do pixel para deixar mais evidente a perda de detalhes nas imagens de baixa resolução.
![Efeitos da redução da resolução espacial [3, p. 21].](imagens/02-formacao/resolucaoespacial.png)
Figura 2.20: Efeitos da redução da resolução espacial [3, p. 21].
A resolução de intensidade ou profundidade corresponde ao número de bits (\(k\)) utilizados para estabelecer os níveis de cinza da imagem (\(L=2^k\)). Por exemplo, em uma imagem cuja intensidade é quantizada em \(L= 256\) níveis, a profundidade é de \(k = 8\) bits por pixel.
Os efeitos da redução dos níveis de cinza (profundidade) podem ser vistos na Figura 2.21. A Figura 2.21(a) apresenta \(256\) níveis de cinza (\(k = 8\)). As Figuras 2.21(b) e (c) foram geradas pela redução do número de bits \(k = 4\) e \(k = 2\), respectivamente, mas mantendo a mesma dimensão.
![Efeitos da redução de profundidade [4, p. 19].](imagens/02-formacao/reducaoprofundidade.png)
Figura 2.21: Efeitos da redução de profundidade [4, p. 19].
2.7 Pixels
Os pixels são elementos principais na formação da imagem, sua importância determina topologicamente as características da imagem, nesta seção mostraremos conceitos básicos da topologia da imagem em relação seus elementos (pixels). Em memória computacional os pixels da imagem são representados nos formatos de matrizes (bidimensional ou tridimensional) já abordado na seção Seção 2.5, através delas é permitido aplicar operações sobre seus elementos (pixels), efetuar análises, identificação de padrões, acessar regiões, alterar cores, posições e tamanho tendo como referência espaço projetado usando as coordenadas do plano.
Propriedades topológicas dos pixels da imagem:
- Vizinhança (4, D, 6, 8 e 26)
- Conectividade
- Adjacência
- Caminho
- Componente Conexa
- Borda e Interior
- Medidas de Distância
- Operações Lógico-aritméticas
2.7.1 Vizinhança
As vizinhanças de um elemento (pixels) \(f\) pertencente ao conjunto \(S\) (matriz de pixels) com coordenadas \((x,y)\) possui vizinhos dos tipos 4, D e 8. Para definir uma vizinhança-4 (denotado \([N_4(f)])\) de \(f(x,y)\) ilustrado na Figura 2.22, \(f_{(1,1)}\) possui quatro vizinhos, dois na horizontal e outros dois na vertical cuja as coordenadas da vizinhança são \((x + 1, y), (x - 1, y), (x, y + 1) \ e \ (x, y -1)\). Os quatros vizinhos diagonais de \(f_{(5, 1)}\) são de coordenadas \((x - 1 , y - 1), (x - 1, y + 1), (x + 1, y + 1)\), que constituem o conjunto \([N_d(f)]\). A vizinhança-8 (denotado \([N_8(f)]\) e ilustrada na Figura 2.22 \(f_{(4, 5)}\), é definida como \(N_8(f)= N_4(f) \ U \ Nd(f)\).
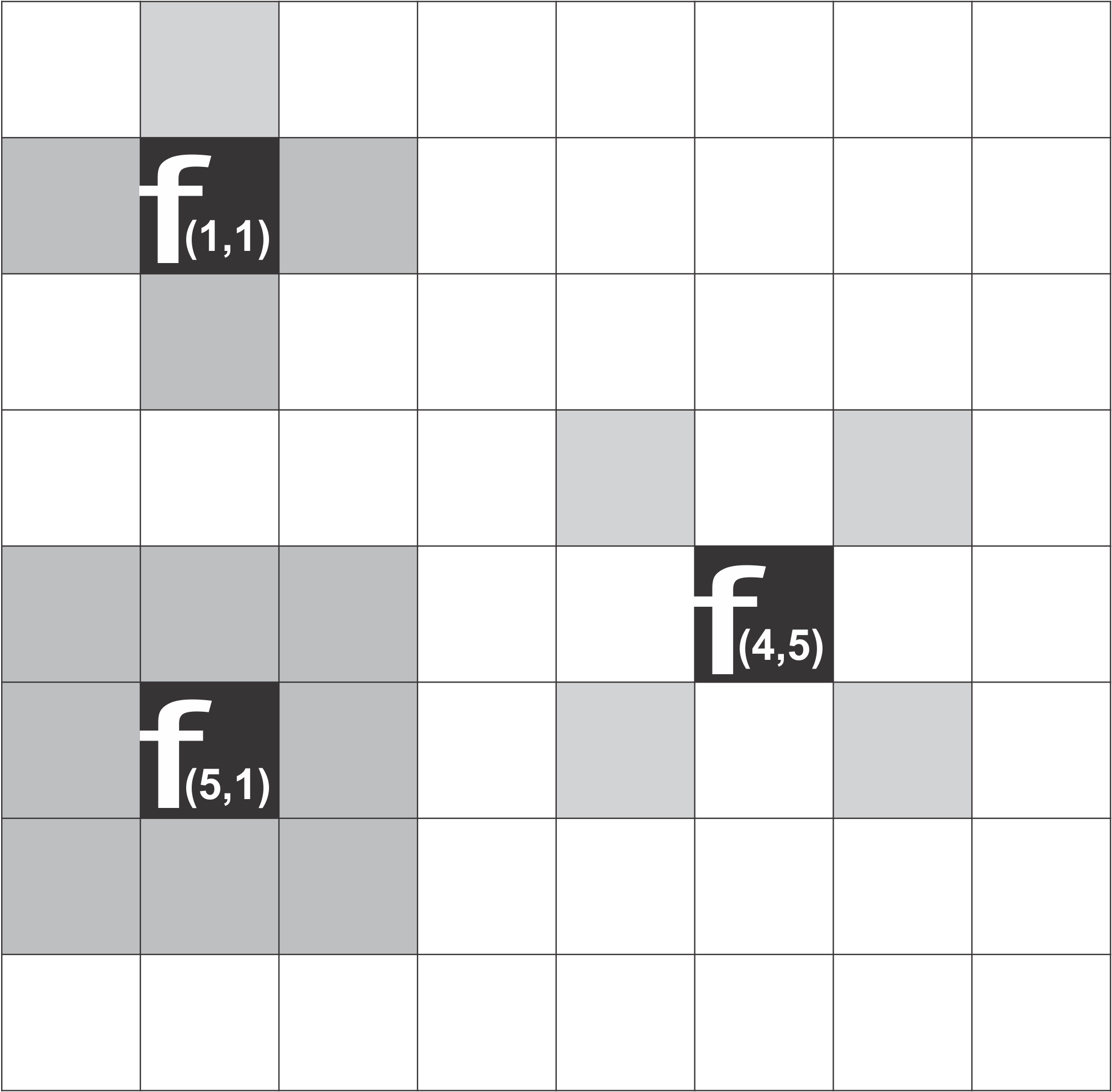
Figura 2.22: Vizinhança de 4-D e 8 de um pixel, matriz de pixel da imagem.
2.7.2 Conectividade
A conectividade entre os pixels é outro conceito importante na topologia da imagem, usada para determinar limites de objetos e componentes de regiões na imagem. Dois pixels são conexos entre si primeiro verificar-se seus tipos de (vizinhos Seção 2.7.1), de seguida se existe similaridade na intensidade de cinza, cor ou textura. Por exemplo, em uma imagem binária, em que os pixels podem assumir os valores \(0\) ou \(1\), dois pixels podem ter vizinhança-4, mas somente serão considerados conexos se possuírem o mesmo valor. [3, p. 31].
2.7.3 Adjacência
Um conjunto \(V\) com valores de intensidade para definir adjacência, em uma imagem binária, com \(V={1}\) e outra imagem com mesmo conjunto contendo escala de nível de cinza no limite \(0\) a \(255\) com vários elementos (pixels) o conjunto \(V\) poderia ser qualquer subconjunto desses \(256\) valores se eles estiverem conectados de acordo com o tipo de (vizinhança Seção 2.7.1) especificado. [2, p. 31].
2.7.4 Caminho
Uma imagem com coordenada de pixels \((x_1 , y_1), (x_2 , y_2) … (x_n , y_n)\) que determina a sequência do caminho dos variados pixels onde né o comprimento do caminho, e \((x_i , y_i)e (x_i + 1 , y_i + 1)\) são adjacentes, tal que \(i = 1,2,...,n - 1\).Se na relação de conectividade considerar vizinhança-4, então existe um caminho-4; para vizinhança-8, tem-se um caminho-8. Exemplo de caminhos são mostrados na Figura 2.23 sendo que o caminho-4 possui comprimento \(10\) e o caminho-8 possui comprimento \(7\). O conceito de caminho também pode ser estendido para imagens tridimensionais. [3, p. 31].
![(a) Caminho-4, (b) Caminho-8. [3, p. 31]](imagens/02-formacao/caminho.png)
Figura 2.23: (a) Caminho-4, (b) Caminho-8. [3, p. 31]
2.7.5 Componente Conexa
Componentes conexos de pixels de uma imagem é um conjunto de elementos (pixels) que de alguma forma estão conectados entre si, dois ou mais pixels são componentes conexos se existir um caminho seção 2.7.4 Caminho pertencente ao conjunto. A Figura 2.24 mostra uma imagem bidimensional contendo três componentes conexos caso seja considerada a vizinhança-4 ou, então, dois componentes conexos se considerada a vizinhança-8. [3, p. 32].
![Componentes Conexos de uma imagem bidimensional [3, p. 32].](imagens/02-formacao/componente_conexos.png)
Figura 2.24: Componentes Conexos de uma imagem bidimensional [3, p. 32].
2.7.6 Borda e Interior
A borda de um componente conexo seção 2.7.5 \(S\) em uma imagem bidimensional é o conjunto de pixels pertencentes ao componente e que possuem vizinhança-4 com um ou mais pixels externos a \(S\) [3, p. 32]. Intuitivamente, a borda corresponde ao conjunto de pontos no contorno do componente conexo. O interior é o conjunto de pixels de \(S\) que não estão em sua borda. A Figura 2.25 mostra um exemplo de uma imagem binária com sua borda interior.
![Borda e interior de um componente, Figura do lado esquerdo, mostra a imagem original, a Figura do lado direito mostra os pixels da borda e interior. [3, p. 32].](imagens/02-formacao/borda_interior.png)
Figura 2.25: Borda e interior de um componente, Figura do lado esquerdo, mostra a imagem original, a Figura do lado direito mostra os pixels da borda e interior. [3, p. 32].
2.7.7 Medidas de Distância
As medidas de distância são aplicadas sobre os pixels e componentes da imagem, considerando \(D\) uma função com os pixels \(f_1\), \(f_2\) e \(f_3\) de coordenadas \((x_1, y_1)\), \((x_2, y_2)\), \((x_3, y_3)\), para verificar se \(D\) é uma função distância ou medida de distância, deve satisfazer as seguintes propriedades:
- \[ D(f_1,f_2) \geq 0 (D(f_1,f_2) = 0 \ se \ f_1 = f_2 \tag{2.9} \]
- \[ (f_1,f_2) = D(f_2, f_1) \tag{2.10} \]
- \[ D(f_1,f_3) \leq D(f_1,f_2) + D(f_2,f_3) \tag{2.11} \]
Aplicabilidade da fórmula Euclidiana uma das formas de satisfazer as propriedades acima, desse modo podemos analisar a métrica de dois ou mais pixels de uma imagem, supondo que os pixels \(f_1 \ e \ f_2\) de coordenadas \((x_1, x_2), (y_1, y_2)\) para medir suas distância aplicamos:
\[D_4(f_1 , f_2) = \sqrt{(x_1-x_2)^2 + (y_1-y_2)^2} \tag{2.12} \]
Na medida de distância Euclidiana, todos os pixels menores ou igual de qualquer valor \(d\) formam um disco de raio \(d\) centro em \(f_1\). Como exemplo, os pontos com distância \(D_E \leq 3\) de um ponto central \((x, y)\) formam o conjunto mostra na Figura: 2.26
![Conjunto de pontos com distância Euclidiana menor ou igual de ponto central. [3, p. 33].](imagens/02-formacao/medida_distancia1.png)
Figura 2.26: Conjunto de pontos com distância Euclidiana menor ou igual de ponto central. [3, p. 33].
A distância \(D_4\) entre \(f_1\) e \(f_2\), também denotada de city-block, é definida como: \[ D_4(f_1 , f_2) = |x_1 - x_2 | + |y_1 - y_2 | \tag{2.13} \]
Os pixels com uma distância \(D_4\) de \(f_4\) menor ou igual a algum valor \(d\) formam um losango centrado em \(f_1\). Em particular, os pontos com distância \(1\) são os pixels com vizinhança-4 de ponto central. Por exemplo, os pontos com distância \(D_4 \leq 3\) de um ponto central \((x, y)\) formam o conjunto mostrado na Figura 2.27
![Conjunto de pontos com distância \(D_4\) menor ou igual a \(3\) de um ponto central [3, p. 33].](imagens/02-formacao/medida_distancia2.png)
Figura 2.27: Conjunto de pontos com distância \(D_4\) menor ou igual a \(3\) de um ponto central [3, p. 33].
A distância \(D_8\) entre \(f_1\) e \(f_2\), também denotado de chessboard, é definida como \(D_8(f_1 , f_2) = max(| x_1 = x_2 | , | y_1 =y_2 |)\) Os pixels com uma distância \(D_8\) de \(f_1\) menor ou igual a algum valor \(d\) formam um quadrado central em \(f_1\). Os pontos com distância \(1\) são os pixels com a vizinhança-8 do ponto central. Por exemplo, os pontos com distância \(D_8 \leq 3\) de um ponto central \((x, y)\) formam o conjunto mostrado na Figura 2.28
![Conjunto de pontos com distância \(D_4\) menor ou igual a \(3\) de um ponto central [3, p. 33].](imagens/02-formacao/medida_distancia3.png)
Figura 2.28: Conjunto de pontos com distância \(D_4\) menor ou igual a \(3\) de um ponto central [3, p. 33].
2.7.8 Operações Lógico-aritméticas
Operações lógicas e aritméticas podem ser utilizadas para modificar imagens. Embora essas operações permitam uma forma simples de processamento, há uma grande variedade de aplicações em que tais operações podem produzir resultados de interesse prático [3, p. 34]. Dadas duas imagens, \(f_1\) e \(f_2\), as operações aritméticas mais comuns entre dois pixels \(f_1(x, y)\) e \(f_2(x, y)\) são a adição, subtração. multiplicação e divisão, definida de acordo com:
Operações Aritméticas:
Adição: \(f_1(x_1, y_1) + f_2(x_2, y_2)\).
Subtração: \(f_1(x_1, y_1) - f_2(x_2, y_2)\).
Multiplicação: \(f_1(x_1, y_1) \cdot f_2(x_2, y_2)\)
Divisão: \(f_1(x_1, y_1) \div f_2(x_2, y_2)\)
Durante o processo de operações aritméticas sobre uma imagem alguns cuidados devem ser tomados para contornar a produção de valores fora do intervalo de níveis de cinza sobre a imagem original no processo. Neste caso, a operação de adição de duas imagens com \(256\) níveis de cinza, pode resultar em um número maior que valor \(255\) para determinados pixels, por outro lado, a operação de subtração de duas imagens podem resultar em valores negativos para alguns pixels durante o processo. Para solucionar esse problema depois do processo aritmético (aplicação aritmética), realizar uma transformação de escala de cinza na imagem resultante para manter seus valores do intervalo adequado [3, p. 34].
Refêrencias
[2] R. C. Gonzalez e R. C. Woods, Processamento digital de imagens, 3º ed. São Paulo: Pearson Prentice Hall, 2010.
[3] H. Pedrini e W. Robson Schwartz, Analise de imagens digitais: principios, algoritmos e aplicações, 3º ed. São Paulo: Thomson Learning Edicoes Ltda, 2007.
[4] T. B. Moeslund, Introduction to video and image processing: Building real systems and applications. Springer Science & Business Media, 2012.
[8] I. C. Cuthill et al., “The biology of color”, Science, vol. 357, nº 6350, 2017.
[9] W. Burger, M. J. Burge, M. J. Burge, e M. J. Burge, Principles of digital image processing, vol. 111. Springer, 2009.
[10] U. Teubner e H. J. Bruckner, Optical Imaging and Photography: Introduction to Science and Technology of Optics, Sensors and Systems. Walter de Gruyter GmbH & Co KG, 2019.
[11] W. Commons, “Bayer pattern on sensor profile”. 2006, [Online]. Disponível em: https://commons.wikimedia.org/wiki/File:Bayer_pattern_on_sensor_profile.svg.
{kind=link}
[12] A. C. Bovik, The essential guide to image processing. Academic Press, 2009.